
[System design] Sharding : In and Out Explained
Database Sharding explained with use cases! + Example of a social media app on how to sharding gets implemented

👋 Hi, this is Venkat, and here with a full issue of the ZenMode Engineer Newsletter. In every issue, I cover one topic explained in simpler terms in areas related to computer systems and tech and beyond.
Imagine this!
A bead of sweat trickled down Anya's temple as she slammed her fist 👊 on the refresh button.
The screen remained stubbornly frozen, displaying the dreaded
"Error: Database Overload" message. 😱
Anya, a data analyst at StreamCo, the hottest new music streaming service, felt a familiar pang of frustration.
Their user base was exploding, but their trusty old database, affectionately nicknamed "The Monolith," was groaning under the weight of millions of music lovers.
"Another crash?" A voice startled Anya.
It was Kai, her partner-in-crime (and coding), with concern etched on his face.
Anya sighed. "Yup. It looks like The Monolith is having a meltdown again. Every time a new wave of users signs up, it takes a nosedive."
Kai ran a hand through his already messy hair. "We need a bigger server, right? Like, a LOT bigger."
Anya shook her head. "We can't just keep throwing hardware at the problem. It's not scalable. We need a smarter solution."
Their conversation was interrupted by a frantic message from their CEO, Sarah.
"The investors are freaking out! We need to fix this or our funding is going down the drain faster than a leaky faucet!"
Anya and Kai exchanged a determined look.
They knew the future of StreamCo depended on finding a solution.
That night, fueled by copious amounts of pizza and code, a daring idea sparked in Anya's mind. "What if," she said, eyes gleaming, "we could break The Monolith into smaller pieces, like... shards?"
Understanding Sharding
In today’s world, data is growing at an enormous rate. Enterprises have built innovative solutions to handle a humongous amount of data.
It’s not uncommon to see data distributed across many machines or databases.
This technique, known as ‘Sharding’, helps build scalable & reliable systems.
In a nutshell, Sharding is a technique used to partition a data store horizontally into smaller, more manageable fragments called shards, distributed across multiple servers or nodes.
This allows us to scale our data stores in terms of storage and computing as the queries and operations on each node are only for a subset of the data i.e. shard.
We'll talk about what database sharding is, how it works, and the best ways to use it.
Before we get into that question, it's essential to understand why we share data stores and the various options you have before you embark on sharding.
🔔Let's consider a social media app like "Chirp."🐤 As Chirp gains popularity, millions of users join the platform, creating a massive amount of data: user profiles, posts, comments, and direct messages.
Initially, Chirp stores all this data in a single database server causing:
Performance Issues: The single server becomes overloaded as the user base grows. When users try to see their friend's posts or search for specific content, queries take longer to process, leading to a frustrating user experience.
Scalability Challenges: Adding more users means even more data. Eventually, the single server reaches its capacity and can't handle the growing data volume. Scaling becomes difficult and expensive.
You see the problem now, when we need to find a user profile from this database, each time around (approx. 100K transactions) have to be done to find the profile, which is very very costly.
What is it to shard a database mean?
We already know now that, sharding is a method for distributing data across multiple machines.
Sharding becomes especially handy when no single machine can handle the expected workload.
Sharding is an example of horizontal scaling, while vertical scaling is an example of just getting larger and larger machines to support the new workload.

Like any distributed architecture, database sharding costs money.
Setting up shards, keeping the data on each shard up to date, and ensuring requests are sent to the right shards is time-consuming and complicated.
Before you start sharding, you might want to see if one of these other options will work for you.
What are my options before sharding?
It's tempting to overcomplicate things early on, but a straightforward approach makes it easier to adapt your application as it grows.
If throwing more resources (like bigger servers) at the problem makes it disappear, that's usually the way to go for now. But ensure the existing setup was running as efficiently as possible.
But, let us understand the several strategies you can explore to improve performance and scalability without the added complexity of sharding.
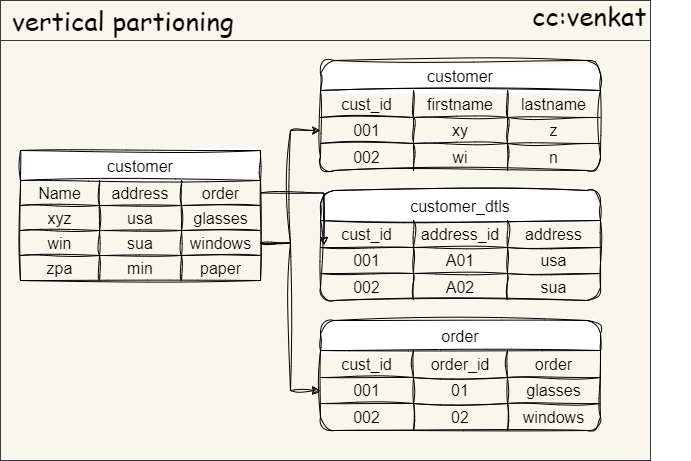
⭕Option 1. Vertical Partitioning
This technique involves splitting a single table into multiple, smaller tables based on logical boundaries within the data.
Imagine a large table storing user information (name, email, address, purchase history). Vertical partitioning could separate this data:
One table for basic user information (name, email).
Another table for user addresses.
A separate table for purchase history.
This approach reduces the size of individual tables, leading to faster queries that only need to access the relevant table. It also simplifies maintenance and backups as you're managing smaller data units.
⭕Option 2. Database Optimization:
Optimizing your existing database can often yield significant performance improvements.
Techniques like:
Indexing: Creating indexes on frequently used columns allows for faster retrieval of specific data.
Query Tuning: Analyzing and optimizing queries to reduce their complexity and execution time.
Hardware Upgrades: Upgrading your server hardware (CPU, RAM) can temporarily boost performance.
⭕Option 3. Database Replication:
This involves creating a copy of your database on another server.
This allows read requests to be distributed between the primary database and the replica, reducing the load on the main server.
While not a direct scaling solution, it can improve read performance and offer redundancy in case of a primary server failure.

⭕Option 4. Caching:
Caching frequently accessed data in memory can significantly improve response times for those queries.
By storing commonly used data readily available, the database doesn't need to perform the same queries repeatedly, leading to a faster user experience.
Implementation Consideration
Sharding isn't a one-size-fits-all solution.
The cornerstone of successful sharding lies in a well-defined data model that facilitates logical partitioning.
This necessitates the identification of an optimal sharding key, an attribute that governs the effective distribution of data records across individual shards (database partitions).
❗❗Here are some factors to consider before implementing it:
Data Model Compatibility: Sharding shines when your data lends to logical partitioning. Grouping tools by type (hammers, saws, screwdrivers) makes sense.
But imagine, organizing a random assortment of items becomes a logistical nightmare. Similarly, your data model needs to be conducive to clear categorization based on a chosen "sharding key" (attribute) — we will understand it in detail — for sharding to be truly effective.The Crucial Sharding Key: Selecting the right sharding key is akin to labeling your items at the garage sale. A clear label (key) ensures everyone knows exactly where a wrench belongs (which shard). Choosing the wrong key creates confusion – a wrench mistakenly placed amongst the gardening tools (inefficient data access).
A well-defined sharding key based on frequently used attributes (e.g., user ID, location) is critical for efficient data retrieval.
Increased Management Overhead: Sharding adds an extra layer of complexity compared to a single server setup. Imagine maintaining a detailed map of your garage sale, indicating where each item category resides across multiple stalls (shards).
Similarly, sharding requires a "shard mapping" system to track data location and coordinate queries across multiple servers. This introduces additional management overhead that needs to be factored in.
Let’s deep dive into key concepts and how they work behind the scenes.
Key Sharding concepts (What is?):
🍀Shards
Imagine a large e-commerce store with a massive "products" table storing information about millions of items.
→ Sharding allows you to split this table horizontally based on a chosen attribute. One approach could be to partition the table by product category (electronics, clothing, etc.).
Each shard (partition) would then be a replica of the original "products" table structure, but containing only data for a specific category.
These individual shards would reside on separate MySQL servers, enabling parallel processing of queries.
Shards are individual partitions of your original database table, each residing on a separate MySQL server instance.
🍀Sharding Key
In our e-commerce scenario, the "product_category" attribute would be the sharding key.
Each product record would have its category specified (electronics, clothing), and this category value would determine the shard location (MySQL server) where the product information resides. For instance, a product record for a smartphone (category: electronics) would be stored in the shard specifically dedicated to electronic products on a separate MySQL server.
The sharding key is the crucial attribute that dictates which shard a particular data record belongs to. It acts as a guiding principle, directing each product record to its designated shard.
🍀Shard Mapping

Now the e-commerce platform has a separate system (shard map) that meticulously records the mapping between product categories (sharding key) and the corresponding MySQL server hosting the shard (partition) for that category.
When a customer searches for a specific product (query), the application uses the product category (sharding key) to consult the shard map.
The shard map then identifies the relevant MySQL server (shard) containing the product information for that category. The application then directs the query to the identified shard server for efficient retrieval of product details.
Shard mapping plays a critical role in efficiently routing queries to the appropriate shard. It acts as a navigation system, pinpointing the specific shard location based on the sharding key value.
Sharding Strategies
Before we can Shard a database, we need to answer a few important questions. Your plan will depend on how you answer these questions.
How do we distribute the data across shards?
What Strategies to choose and apply?
The choice of strategy depends on factors like data access patterns, query complexity, expected growth rate, and infrastructure constraints.
Some key considerations include:
Data locality: How closely related are records within each partition? If they share common attributes or relationships, keeping them together may simplify queries and improve performance.
Load balancing: Ensuring an equal distribution of workload across all nodes reduces bottlenecks and improves overall throughput.
Scalability: Consider future expansion requirements when choosing a sharding strategy. Can it accommodate increased demand without significant reconfiguration or downtime?
Query simplicity: Minimizing cross-shard joins and transactions can help maintain high levels of concurrency and prevent potential consistency issues.
Maintenance costs: Evaluate the operational overhead associated with managing complex sharding configurations versus simpler alternatives
There are various approaches to sharding a database, each with its advantages and considerations:
🟢Hash Sharding:
Uses a hashing function on the sharding key to assign data to a shard. Efficient for uniformly distributed data.
A hashing function is like a magic spell that takes the sharding key value (marble's color) as input and produces a unique numerical output (hash value).
This hash value typically acts as a compressed representation of the original sharding key.
Common hashing functions used for sharding include MD5 and SHA-1.
Consider the same e-commerce platform with a customer table and millions of customer records. You decide to use "customer_id" as the sharding key and implement hash sharding with 10 shards (baskets). Here's how customer data would be distributed:
Customer 1:
"customer_id" (sharding key): 12345
Hashing function output (hash value): Let's assume the hashing function produces a hash value of 48721.
Modulo operation: 48721 % 10 (number of shards) = 1
Customer 1 with "customer_id" 12345 is assigned to shard number 1.
Customer 2:
"customer_id" (sharding key): 54678
Hashing function output (hash value): Assume the hash function produces a value of 23459.
Modulo operation: 23459 % 10 = 9
Customer 2 with "customer_id" 54678 is assigned to shard number 9.
⭐⭐Considerations for Hash Sharding:
Hash Function Selection: The choice of hashing function can impact the distribution of data across shards. It's essential to select a collision-resistant hashing function that minimizes the possibility of two different sharding key values producing the same hash value (collision).
Uniform Key Distribution: Hash sharding works best when the chosen sharding key has a uniform distribution of values. If the distribution is skewed (e.g., most customer IDs fall within a specific range), it can lead to uneven shard sizes and potential performance issues.
Shard Rebalancing: As data volumes grow, shard sizes might become unbalanced over time. Rebalancing strategies are necessary to periodically redistribute data across shards and maintain optimal performance.
🟢Range Sharding
Splits data based on a continuous range of the sharding key (e.g., date ranges). Useful for time-series data.
Sharding Key: Defining the Ordering
The sharding key acts as the sorting criterion, akin to the Dewey Decimal Classification system in libraries. It determines the order in which data records are stored. Common sharding keys for range sharding include date ranges (e.g., years, quarters), numerical values (e.g., user IDs within a specific range), or alphabetical sequences (e.g., user names).
Defining Shard Ranges: Creating Ordered Segments
The entire data spectrum for the chosen sharding key is divided into contiguous ranges. These ranges define the boundaries for each shard.
For instance, with a date range sharding key, you might define shards for specific years (2020-2021, 2022-2023, etc.).
Assigning Data to Shards: Matching the Range
Each data record is assigned to a specific shard based on the value of its sharding key. The shard's range determines the "home" for the data record.
Imagine a library with separate sections for books published between 2000-2010, 2011-2020, and so on. A book published in 2005 would reside in the 2000-2010 section (shard).
You decide to use "user_id" (a numerical value) as the sharding key and implement range sharding with three shards:
Shard 1: User IDs: 1 - 1,000,000
Shard 2: User IDs: 1,000,001 - 2,000,000
Shard 3: User IDs: 2,000,001 - onwards
Here's how user data would be distributed:
A user with ID 543,210 would be assigned to shard 2 since their ID falls within the 1,000,001 - 2,000,000 range.
Retrieving data for this user would involve querying shard 2 specifically.
⭐⭐Considerations for Range Sharding:
Choosing the Right Sharding Key: Selecting an appropriate sharding key with natural order and predictable growth patterns is crucial. Using a poorly chosen key can lead to uneven shard sizes and performance bottlenecks.
Shard Boundary Management: As data volume grows, shard boundaries might need to be adjusted to maintain balanced shard sizes. This can involve splitting or merging shards to ensure optimal performance.
Tailored for Specific Queries: Range sharding shines when queries frequently target specific data ranges based on the sharding key. If queries involve random data access patterns, it might not be the most efficient approach.
🟢Directory-Based Sharding(Lookup-based): Maintains a central directory mapping data to specific shards. Offers flexibility but adds complexity.

Sharding Key
As with other sharding techniques, a sharding key is chosen. This key can be any attribute that effectively identifies a data record and can be used for efficient retrieval. Common sharding keys for directory-based sharding include user ID, location, or a specific data element (e.g., product category).
Shard Mapping Table: The Centralized Directory
The heart of directory-based sharding is the shard mapping table (directory). This table acts like the library's card catalog, meticulously recording the mapping between sharding key values and the corresponding shard location (server) where the data resides.
Each entry in the shard mapping table typically includes the sharding key value and the shard ID (or server address) where the data record is stored.
Data Access with a Lookup:
When an application needs to access data, it first consults the shard mapping table (directory). It uses the sharding key of the data record to perform a lookup in the table.
Based on the sharding key value, the lookup retrieves the corresponding shard ID (server address) from the shard mapping table.
The application then directs the query to the identified shard server for efficient data retrieval.
You decide to use "customer_location" (e.g., country) as the sharding key and implement directory-based sharding:
Sharding Key (Customer Location) → Shard ID (Server Address)
USA → Shard 1 (Server A)
Europe→ Shard 2 (Server B)
Asia- >Shard 3 (Server C)
A customer from France (Europe) would have their data stored on Shard 2 (Server B) based on the mapping in the Shard mapping table.
⭐⭐ Considerations for Directory-Based Sharding:
Lookup Overhead: Every data access involves an additional lookup in the shard mapping table, which can introduce some overhead compared to other sharding techniques.
Single Point of Failure: The shard mapping table becomes a critical component, and its failure can disrupt data access. Implementing redundancy measures for the shard mapping table is crucial.
Increased Complexity: Managing and maintaining the shard mapping table adds complexity to your database administration tasks.
Scenario
Chirp., a social media app, is struggling with performance limitations due to a single overloaded MySQL database server. The constant growth of its user base and the surge in read/write operations are causing slow queries, particularly for features like user feeds and friend searches.
These delays hinder user experience and can potentially stall growth.
To address these scalability bottlenecks, the engineering team at Chirp decides to shard the MySQL database horizontally. Sharding essentially partitions the data into self-contained units called shards, each residing on a separate MySQL server.
This approach distributes the load across multiple servers, improving overall database performance and scalability.
Scenario 1: Location-based Sharding
