


How do transformers work?+Design a Multi-class Sentiment Analysis for Customer Reviews
We will deep dive into understanding how transformer model work like BERT(Non-mathematical Explanation of course!). system design to use the transformer to build a Sentiment Analysis

👋 Hi, this is Venkat and here with a free, full issue of the The ZenMode Engineer Newsletter. In every issue, I cover one topic explained in a simpler terms in areas related to computer technologies and beyond.
Transformers have become synonymous with cutting-edge AI, particularly in the realm of natural language processing (NLP).
But what exactly makes them tick? How do these models navigate the intricacies of language with such remarkable efficiency and accuracy?
Buckle up, because we're about to learn the heart of the transformer architecture.
But.. Before we deep dive into it lets understand where its been used.. if you have used google translate/ ChatGPT both rely on these.
Google Translate: This widely used platform relies heavily on transformers to achieve fast and accurate translations across over 100 languages. It considers the entire sentence context, not just individual words, leading to more natural-sounding translations.
Netflix Recommendation System: Ever wondered how Netflix suggests shows and movies you might enjoy? Transformers analyze your viewing history and other users' data to identify patterns and connections, ultimately recommending content tailored to your preferences.

The Big Picture: Encoder and Decoder Dance
Imagine a factory, but instead of assembling physical objects, it processes language. This factory has two main departments:
The Encoder: This is the information extractor, meticulously dissecting the input text, understanding its individual elements, and uncovering the hidden connections between them.
The Decoder: Armed with the encoder's insights, the decoder crafts the desired output, be it a translated sentence, a concise summary, or even a brand new poem.
Encoder: Decoding the Input Labyrinth
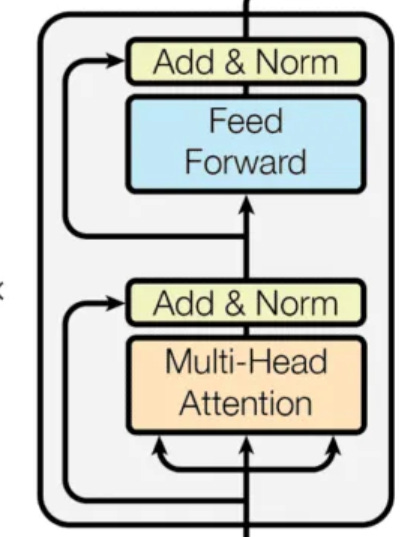
The encoder's journey begins with Input Embedding, where each word is transformed from its textual form into a numerical representation (vector). Think of it as assigning each word a unique identifier.
Consider this example.
Input Text: The process begins with the raw text sentence, such as "The cat sat on the mat."
Input Embedding Layer:
This layer acts as a translator, converting each word into a numerical vector.
Imagine a large dictionary where each word has a corresponding vector address.
These vectors capture various aspects of word meaning:
Semantic relationships (e.g., "cat" is closer to "pet" than "chair").
Syntactic roles (e.g., "cat" is often a noun, while "sat" is a verb).
Context within the sentence (e.g., "mat" here likely refers to a floor mat).
Vector Representation:
The output of this layer is a sequence of numerical vectors, each representing a word:
"The" -> [0.2, 0.5, -0.1, ...]
"cat" -> [0.8, -0.3, 0.4, ...]
"sat" -> [-0.1, 0.7, 0.2, ...]
...
But the encoder doesn't stop there. It employs the following key mechanisms to delve deeper:
Self-Attention Layer: This is the game-changer. Imagine shining a spotlight on each word, but instead of illuminating it in isolation, you also highlight how it connects to all other words in the sentence. This allows the encoder to grasp the context, nuances, and relationships within the text, not just the individual words.

ref from Raimi Karim blog (used only to refernce) Consider this example sentence again "The quick brown fox jumps over the lazy dog."
Word Embeddings: First, each word is transformed into a numerical representation called a "word embedding." Think of it as assigning each word a unique identifier in a giant vocabulary map.
Query, Key, Value: Next, the Self-Attention mechanism creates three special vectors for each word:
Query (Q): This vector asks "What information do I need from other words?"
Key (K): This vector acts like a label, saying "This is the information I have to offer."
Value (V): This vector holds the actual information, like the word's meaning and context.
Attention Scores: Now comes the interesting part. The Self-Attention layer compares the Query vector of each word with the Key vectors of all other words in the sentence.
This helps it understand how relevant each word is to the current word. Based on this comparison, it calculates an attention score for each pair of words.
Imagine shining a spotlight on each word. The brighter the spotlight on another word, the higher the attention score, meaning the more relevant that word is to the current word.
Weighted Values: Finally, the Self-Attention layer uses the attention scores to weigh the Value vectors of all other words. Words with higher attention scores get more weight, contributing more to the final representation of the current word.
Think of it like taking a weighted average of the information from other words, where the weights are determined by how relevant they are.
New Word Representation: By considering the context provided by other words, the Self-Attention layer creates a new, enriched representation of each word. This new representation captures not just the word's own meaning, but also how it relates to and is influenced by other words in the sentence.
Multi-Head Attention: This is like having multiple teams of analysts, each focusing on different aspects of the connections between words. It allows the encoder to capture various facets of the relationships, enriching its understanding.
Sentence: "The quick brown fox jumps over the lazy dog."
Individual Heads: Instead of one Self-Attention mechanism, Multi-Head Attention uses several independent "heads" (often 4-8). Each head has its own set of Query, Key, and Value vectors for each word.
Diverse Attention: Each head computes attention scores differently, focusing on various aspects of word relationships:
One head might attend to grammatical roles (e.g., "fox" and "jumps").
Another might focus on word order (e.g., "the" and "quick").
Another might capture synonyms or related concepts (e.g., "quick" and "fast").
Combining Perspectives: After each head generates its own weighted values, their outputs are concatenated. This combines the diverse insights from different attention mechanisms.
Final Representation: This combined representation holds a richer understanding of the sentence, incorporating various relationships between words, not just a single focus.
Positional Encoding: Since transformers don't process word order directly, this layer injects information about each word's position in the sentence. It's like giving the analysts a map so they know the order in which to consider the words.
Sure, let's delve into positional encoding using an example sentence:
Sentence: "The quick brown fox jumps over the lazy dog."
Here's how positional encoding works step-by-step:
Word Embeddings:
Each word ("The", "quick", etc.) is converted into a numerical representation called a word embedding, like a unique identifier in a vast vocabulary map.
Imagine these embeddings as vectors:
"The": [0.2, 0.5, -0.1, ...]
"quick": [0.8, -0.3, 0.4, ...]
"brown": [..., ...]
...
Positional Information:
Each word's embedding is combined with additional values based on its position in the sentence.
These values are calculated using sine and cosine functions at different frequencies:
Lower frequencies capture long-range dependencies (e.g., "quick" and "fox" are related).
Higher frequencies encode short-range relationships (e.g., "jumps" and "over" are close).
Think of these additional values as "position vectors":
"The": [position 1 vector]
"quick": [position 2 vector]
"brown": [position 3 vector]
...
Combining Embeddings and Positions:
The original word embedding and the position vector are added together, creating a new, enriched representation for each word:
"The": [0.2, 0.5, -0.1, ...] + [position 1 vector] = new enriched embedding
"quick": [0.8, -0.3, 0.4, ...] + [position 2 vector] = new enriched embedding
"brown": [..., ...] + [position 3 vector] = new enriched embedding
...
Understanding Order:
Even if the sentence order changes (e.g., "Dog lazy jumps..."), the position vectors ensure relative positions are maintained.
The model can still learn that "jumps" is more related to "over" than, say, "The".
Feed Forward Network(FFN): This adds a layer of non-linearity, enabling the model to learn more complex relationships that might not be easily captured by attention mechanisms alone.
You've already delved into the sentence through previous layers. You understand individual words, their relationships, and their positions. Now, the FFN arrives like a detective magnifying glass, ready to uncover intricate details not immediately visible.
The FFN does this through three key steps:
Non-linear Transformation: Instead of straightforward calculations, the FFN uses non-linear functions like ReLU to add complexity. Think of it as applying a special filter to the existing information, revealing hidden patterns and connections that simple arithmetic might miss. This allows the FFN to capture more nuanced relationships between words.
Multi-layered Analysis: The FFN isn't just one step; it's typically a chain of two or more fully connected layers. Each layer builds upon the previous one, transforming the information step-by-step. Imagine you're examining the sentence under increasing magnification, uncovering finer details with each layer.
Dimensionality Shift: The FFN expands the information's size (e.g., from 512 dimensions to 2048) in the first layer. This allows it to analyze a wider range of features and capture more complex patterns. Think of it as spreading out the information on a larger canvas for deeper examination. Then, it contracts it back to the original size (e.g., 512 again) in the final layer to ensure compatibility with subsequent layers.
Applying this to our sentence:
Imagine the FFN helps identify that "quick" and "brown" not only describe the "fox" but also subtly connect to its perceived speed through their combined meaning.
Or, it might delve deeper into the relationship between "jumps" and "over," understanding the action and spatial context beyond just their individual definitions.
Repeat, Refine, Repeat: These layers (self-attention, multi-head attention, etc.) are stacked and repeated multiple times. With each iteration, the encoder refines its understanding, building a comprehensive representation of the input text.


Decoder: Weaving the Output Tapestry
Now, the decoder takes the baton. But unlike the encoder, it has an additional challenge: generating the output word by word without peeking at the future. To achieve this, it utilizes:
Masked Self-Attention: Similar to the encoder's self-attention, but with a twist. The decoder only attends to previously generated words, ensuring it doesn't cheat and use future information. It's like writing a story one sentence at a time, without knowing how it ends.
Encoder-Decoder Attention: This mechanism allows the decoder to consult the encoded input, like referring back to a reference document while writing. It ensures the generated output stays coherent and aligned with the original text.
Multi-Head Attention and Feed Forward Network: Just like the encoder, these layers help the decoder refine its understanding of the context and relationships within the text.
Output Layer: Finally, the decoder translates its internal representation into the actual output word, one by one. It's like the final assembly line, putting the pieces together to form the desired outcome.
Beyond the Basics:
Remember, this is just a glimpse into the fascinating world of transformers. The specific architecture can vary depending on the task and dataset, with different numbers of layers and configurations.
Additionally, each layer involves complex mathematical operations that go beyond the scope of this explanation.
But hopefully, this has equipped you with a fundamental understanding of how transformers work and why they have revolutionized the field of NLP.
So, the next time you encounter a seamless machine translation or marvel at the creativity of an AI-powered text generator, remember the intricate dance of the encoder and decoder within the transformer, weaving magic with the power of attention and parallel processing.
Paper: https://arxiv.org/abs/1706.03762
System Design Overview:
Build a Multi-class Sentiment Analysis for Customer Reviews (classifying reviews as positive, neutral, negative, or mixed)
Keep reading with a 7-day free trial
Subscribe to The ZenMode to keep reading this post and get 7 days of free access to the full post archives.