
Connection Pooling — How, what and why? [Case study]
We will learn and understand in this deep dive how a connection pool works and have practical tips on how to set it up correctly

👋 Hi, this is Venkat and here with a full issue of the The ZenMode Engineer Newsletter. In every issue, I cover one topic explained in a simpler terms in areas related to computer technologies and beyond.
Imagine this….
It's Prime Day!
You've been refreshing your Amazon cart for weeks, strategizing the perfect checkout blitz.
The clock strikes midnight, and you unleash your fingers, clicking "Add to Cart" like a maestro conducting a shopping symphony.
But wait... the page freezes!
Panic sets in as the error message taunts you: "Server Overload."
Visions of limited-edition deals slipping away flash before your eyes.
As an engineer, your mind races, dissecting the potential causes.…
What could have caused this ?
… But your friend, ever the jokester, chimes in with a mischievous grin:
"It's gotta be the database!"😂
(a large e-commerce website like Amazon experiencing thousands of concurrent user requests per second (on sale day).
Each request might involve product searches, adding items to the cart, checking out, etc., each requiring communication with the database.
ahh.. you think that the database communication could be the culprit!)
But out of curiosity… how do you handle this?..
and while searching… you found
Concept of connection pooling! (the scaling magic)

I came across connection pooling again recently when I was working on a large scale system (mostly microservice) and realized its impact on performance even when you are talking about serving a couple of hundred users.
Having worked with lots of ORM (hibernate) in my earlier career I didn’t understand the importance of it and how it actually help applications to scale and handle resources(like connections) efficiently.
But first what is a connection?
A connection can be formally defined as a way for a client to talk with the server. It is required to send commands and receive a result.
In the current context, it can be..
Network Connection: The pathway between your device and the web server, allowing you to access and interact with the application online. Think of it as the internet highway leading to your destination.
Database Connection: A temporary "tunnel" between your app and the database for data exchange. Imagine a dedicated line for sending and receiving information.(This is what we going to dig deeper).

But first .. What is the problem with normal Database connections?
Assume a app relies heavily on a MySQL database to store song information, user accounts, and playlists. Each time a user searches for a song, plays a track, or manages their library, your app needs to send queries to the database.
select songs from playlists;
To get the result, along with this query we need to provide the database details and our authentication details, usually the host, port, database, username and password.
These are needed because before actually running the query, the program has to:
find the database
connect to it and authenticate our connection
use the given db and table info.
and then run our query.
Once the result is returned the connection is closed.
When we want to run a different query we need to start over again.
As you can see we this is time consuming. Authentication is a very expensive process and most of the times creating connections take relatively more time compared to the actual query they run.
Every open connection consumes server resources on the database side.
As connections pile up, your database can become overwhelmed, causing bottlenecks and potential downtime during peak activity.
So it becomes very inefficient for us to create a connection for every query.
So instead of closing the connection, keeping it active and running all the queries using the same connection gets rid of the creation latency.
But in a service, how do we share a connection between different clients? That is where connection pooling comes in.

To understand it in very simple terms..
Imagine your app receives 1000 concurrent user requests per second.
Without connection pooling, establishing new connections could add 10 milliseconds of delay, resulting in a response time of 10 seconds.
With connection pooling, this delay might drop to 2 milliseconds, decreasing the overall response time to 2 seconds – a fivefold improvement!😍
Without connection pooling, every request would need to establish a new connection, leading to:
→ Slow response times: Establishing connections consumes resources and takes time, causing delays for users.
→ Resource exhaustion: Creating too many connections can overwhelm the database server, leading to crashes or instability.
→ Scalability issues: Handling increased traffic becomes extremely difficult with conventional connection management.
Connection Pooling
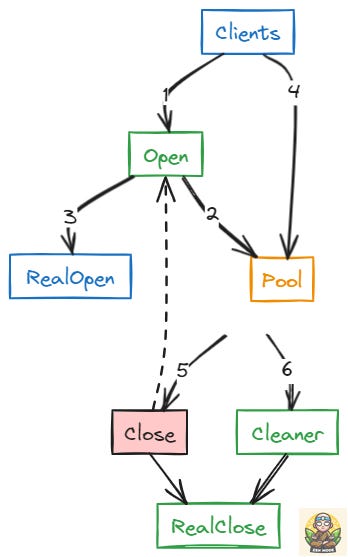
Connection Pooling alleviates this problem by creating a pool of connections at the start and keeping them alive (i.e not closing the connections) till the end.
Whenever some part of the application wants to query the database, they borrow the connection from the pool and once they are done with the query instead of closing the connection, it is returned back to the pool.
As simple as that.
While database connection pooling can help improve application performance, it’s not a one-size-fits-all solution.
Depending on the specifics, it may not be a solution at all. Since there are resource costs associated with both opening/closing connections and maintaining open connections, whether or a connection pool is a good idea will depend on a number of specific factors, including (but not limited to):
Our application and how it interacts with the database
How often it interacts with the database (i.e. scale)
Our database technology of choice
The hardware specs of our database servers
Network latency

Once we’re at sufficient scale, it does often make sense to pool connections, but that raises new questions:
how do I actually create a connection pool, and what size should it be?
What things should I consider?
While the core principle of connection pooling involves reusing established connections for efficiency, there's a whole world of advanced features and considerations to optimize performance and security.
Let's delve deeper with examples:
1. Connection Types:
Imagine an online banking application. Here, we might have two connection pools:
Read-only pool: Optimized for retrieving account balances, transaction history, or other frequently accessed data, minimizing resource usage.
Write-only pool: Dedicated to performing updates, transfers, or other write-intensive operations, ensuring higher concurrency and data integrity.

Read pool vs the write pools (for postgres) - HCL docs By segregating connections based on needs, we optimize overall pool performance and cater to specific workload demands.

2. Advanced Management(connection preheating):
Consider a high-traffic e-commerce site experiencing fluctuating user demands. Here, connection preheating can shine:
During low traffic periods, idle connections in the pool execute minimal "ping" queries to keep them active and responsive when a surge hits.
This eliminates the initial performance dip associated with reactivating cold connections, ensuring instant response even during peak hours.
Furthermore, connection load balancing distributes requests across available connections within the pool. This prevents overloading specific connections and promotes even resource utilization.
3. Monitoring and Adaptation:
Monitoring goes beyond just tracking pool size and activity. Consider these metrics:
Response times: Identify slow connections or bottlenecks within the pool for targeted adjustments.
Wait times: Monitor how long users wait for an available connection, indicating potential pool size limitations.
Error rates: Analyze connection errors to identify issues like authentication failures or database problems for proactive resolution.
Based on these metrics, you can fine-tune pool size, adjust validation frequency (checking idle connections for liveness), or set optimal timeout values for inactive connections. Remember, it's an ongoing process of analyzing and adapting for optimal performance under varying loads.
4. Security Considerations:
Security remains paramount even within connection pools:
Implement robust authentication and authorization mechanisms that control access to specific connections based on user privileges.
Encrypt sensitive data transmitted between the application and the database, even when using connections within the pool. Don't let shared connections compromise sensitive information.
How to create and size connection pools (strategy)
First, we don’t need to try to build a connection pool from the ground up.
Depending on the language of our application and our database technology of choice, there are likely to be good connection pooling frameworks already available.
For example, there’s pgxpool for Go applications using Postgres-compatible databases, etc.
JDBC in Java: The DriverManager class and DataSource interface provide connection pooling functionality in Java. Consider using connection pooling libraries like HikariCP for advanced features and fine-grained control.
ORM frameworks: Many Object-Relational Mapping (ORM) frameworks like Hibernate integrate seamlessly with connection pooling, simplifying its usage and management within your application.
Cloud-based deployments: Cloud platforms often offer managed database services with built-in connection pooling, reducing configuration overhead and simplifying scaling.
leverage Amazon RDS (Relational Database Service):
Built-in connection pooling: You don't need to configure or manage a separate connection pool. RDS automatically handles it, saving you time and effort.
Seamless scaling: The pool size automatically scales up or down based on your application's traffic, ensuring optimal performance under fluctuating loads.
Simplified management: You manage everything through the AWS console or API, focusing on your application logic rather than low-level database configurations.
How do we decide on pool size to set?
Unfortunately, there's no one-size-fits-all answer to calculating the right connection pool size and optimizing it for 100 million concurrent users.
It depends heavily on various factors specific to your application and environment.
But first ..Why not… open maximum pools at start?
When using a connection pool, we have to balance the cost trade-offs between keeping connections open and opening/closing new connections.
We want to size our connection pool such that the number of idle connections is minimized, but so is the frequency with which we have to open/close new connections. We also want to be sure that the maximum number of connections is appropriate, as this reflects the max work that your database can do.
If we make the pool too small (i.e. choose too few connections), we’ll introduce latency, as operations have to wait for an available connection to open up before they can execute. On the other hand, if we choose too many connections, that can also create latency for reasons that relate to how each processor core in a server typically executes threads.
Understanding Your Environment:
Database type: Different databases have different performance characteristics and connection overhead. Understanding your database's specific behavior is crucial.
Application workload: Analyze the types of queries your application executes, their average execution time, and the frequency of database interactions per user.
Resource constraints: Consider available memory, CPU, and network bandwidth on your database server and application servers.
Expected concurrent users: While aiming for 1 million, understand peak usage patterns and potential bursts.
Monitoring capabilities: Ensure you have robust monitoring tools to track pool usage, connection wait times, and overall application performance.
Approaches to Sizing:
Start small and scale: Begin with a conservative pool size, say 10-20 connections, and monitor usage metrics. Gradually increase the pool size based on observed peak usage and response times, avoiding resource exhaustion.
Utilize formulas (cautiously): Some formulas recommend pool size based on expected users and average connection lifetime. However, use these with caution as they may not capture your specific workload nuances.
Load testing and benchmarking: Conduct realistic load tests with varying user counts to observe pool behavior and pinpoint optimal size.
Optimization Strategies:
Connection validation: Regularly check idle connections for liveness to avoid using stale ones.
Connection timeout: Set appropriate timeouts for inactive connections to prevent resource lockup.
Connection preheating: For high-throughput scenarios, consider preheating idle connections with minimal queries to keep them active and responsive.
Load balancing: Distribute requests across available connections within the pool for even resource utilization.
Fine-tuning pool settings: Based on monitoring data, adjust parameters like minimum/maximum pool size, validation frequency, and timeout values for optimal performance.
Remember:
→ Monitor and iterate: Optimization is an ongoing process. Continuously monitor performance metrics and adjust pool configuration based on observed behavior.
→ Seek expert advice: If dealing with complex scenarios or critical applications, consider consulting database performance experts (Product specific) for tailored recommendations.
By adopting these practices, the e-commerce platform benefits from the efficiency of connection pooling, translating to a fast, scalable, and responsive user experience even under immense traffic.
This is just one example, and the specific implementation details depend on the chosen technologies, platform, and workload. However, the core principles of connection pooling remain the same across various real-world applications, offering significant performance and scalability advantages.
That’s it !
Case Study: Optimizing Connection Pooling for a Social Media Platform
Background:
Sparkly, a fast-growing social media platform, struggles with increasing response times as its user base surges towards 100 million. The platform relies heavily on its database for user interactions, content storage, and real-time updates. Initial performance analysis reveals frequent database connection overhead as a bottleneck.
Current Scenario:
Expected Concurrent Users: 1 million (peak)
Database: MySQL
Application Framework: Java Spring
Connection Pool: Basic HikariCP configuration with 20 connections
Challenge:
Optimize the connection pool configuration to handle 1-5 million concurrent users without compromising performance, resource usage, or stability.
